这本书主要通过若干代码片段来讲解各个基本概念,实战操作较少。
更新历史
- 2020.02.18:重新上线
- 2019.05.27:完成阅读和读后感
- 2019.05.24:开始阅读
读后感
这本书主要通过若干代码片段来讲解各个基本概念,实战操作较少,不过比较深度浅出把大部分需要注意的内容都点了出来,如果需要进一步学习,还是要更多去写代码和看更加纵向深入的书籍。
阅读笔记
第一章 Spark 数据分析导论
- Spark 是一个用来实现快速而通用的集群计算的平台
- 本书的两大目标读者人群:数据科学家和工程师
第 2 章 Spark 的下载与入门,略
第 3 章 RDD 编程
这里直接给出一些例子,而不进行具体的命令讲解,如果需要可以参考笔记 2019-05-24-循序渐进学Spark.md。
RDD.distinct()生成一个只包含不同元素的新 RDD,但是开销很大,因为需要将所有数据通过网络进行 shuffle,以确保每个元素只有一份,如果想要提高性能,需要尽量 shuffle
计算 RDD 中各值的平方
Python
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect()
for num in squared:
print("%i " % num)Scala
val input = sc.parallelize(List(1, 2, 3, 4))
val result = input.map(x => x * x)
println(result.collect().mkString(","))将行数据切分为单词
Python
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
words.first() Scala
var lines = sc.parallelize(List("hello world", "hi"))
val words = lines.flatMap(line => line.split(" "))
words.first()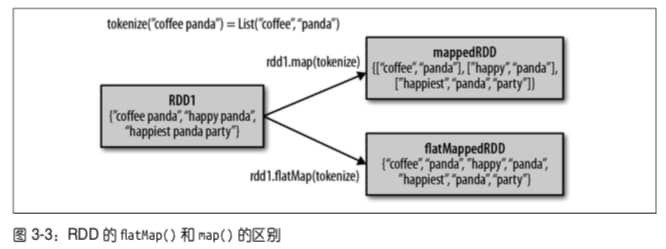
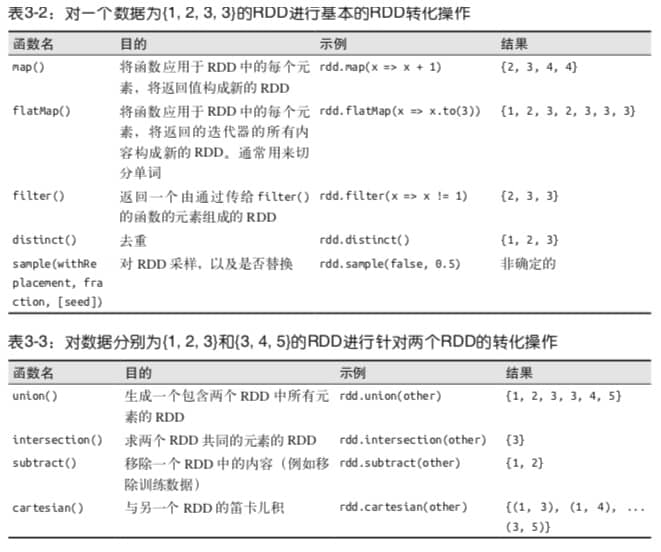
常见 RDD Tranformation 操作
常见 RDD Action 操作

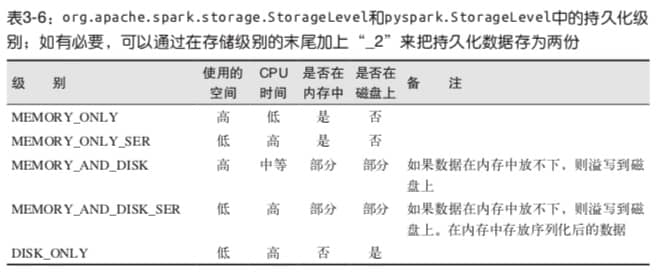
持久化选项
第 4 章 键值对操作
使用可控的分区方式把常被一起访问的数据放到同一个节点上,可以大大减少应用的通信开销。
Pair RDD Transformation 操作


对第二个元素进行筛选
Python
result = pairs.filter(lambda keyValue: len(keyValue[1]) < 20)Scala
pairs.filter{ case (key, value) => value.length < 20 }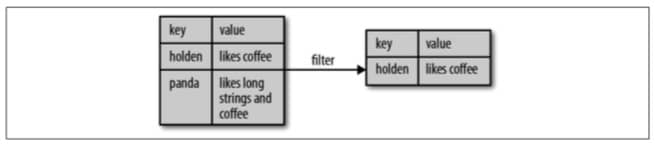
计算每个键对应的平均值
Python
rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))Scala
rdd.mapValues(x => (x, 1)).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))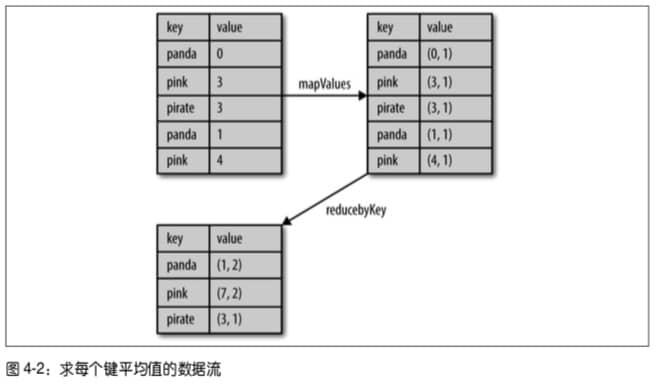
combineByKey() 求每个键对应的平均值
Python
sumCount = nums.combineByKey((lambda x: (x, 1)),
(lambda x, y: (x[0] + y, [1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()Scala
val result = input.combineByKey(
(v) => (v, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
result.collectAsMap().map(println(_))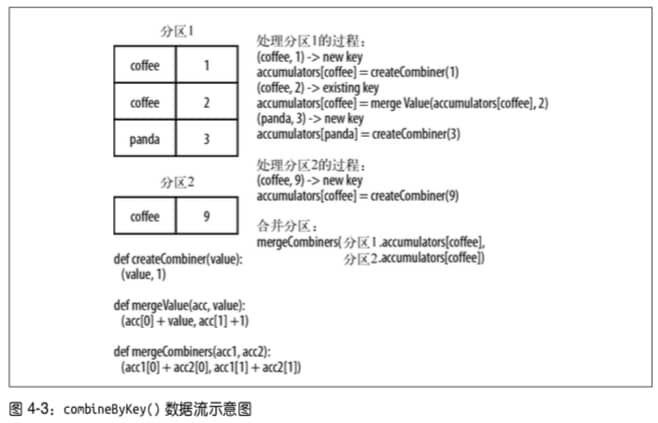
Pair RDD Action 操作

数据分区
在分布式程序中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大地提升整体性能。
这一部分主要是根据数据的分布特性和使用方法进行优化。
第 5 章 数据读取与保存
常见数据源:
- 文件格式(文本文件, JSON, SequenceFile, ProtocolBuffer)与文件系统(NFS, HDFS, S3)
- Spark SQL 中的结构化数据源
- 数据库与 KV 存储(Cassandra, HBase, Elasticsearch, JDBC)
第 6 章 Spark 编程进阶
两种类型的共享变量:
- 累加器 accumulator,对信息进行聚合
- 广播变量 broadcast variable,高效分发较大的对象
具体直接看例子
累加空行
Python
file = sc.textFile(inputFile)
blankLines = sc.accumulator(0)
def extractCallSigns(line):
global blankLines # 访问全局变量
if (line == ""):
blankLines += 1
return line.split(" ")
callSigns = file.flatMap(extractCallSigns)
callSigns.saveAsTextFile(outputDir + "/callsigns")
print("Blank liens: %d" % blankLines.value)Scala
val sc = new SparkContext(...)
val file = sc.textFile("file.txt")
val blankLines = sc.accumulator(0)
val callSigns = file.flatMap(line => {
if (line == "") {
blankLines += 1
}
line.split(" ")
})
callSigns.saveAsTextFile("output.txt")
println("Blank lines: " + blankLines.value)使用广播变量查询国家
Python
signPrefixes = sc.broadcast(loadCallSignTable())
def processSignCount(sign_count, signPrefixes):
country = lookupCountry(sign_count[0], signPrefixes.value)
count = sign_count[1]
return (country, count)
countryContactCounts = (contactCounts
.map(processSignCount)
.reduceByKey((lambda x, y: x+y)))
countryContactCounts.saveAsTextFile(outputDir + "countries.txt")Scala
val signPrefixes = sc.broadcast(loadCallSignTable())
val countryContactCounts = contactCounts.map { case (sign, count) =>
val country = lookupInArray(sign, signPrefixes.value)
(country, count)
}.reduceByKey((x, y) => x + y)
countryContactCounts.saveAsTextFile(outputDir + "/countries.txt")- 第 7 章 在集群上运行 Spark
- 第 8 章 Spark 调优与调试
- 第 9 章 Spark SQL
- 第 10 章 Spark Streaming
- 第 11 章 基于 MLlib 的机器学习
这几章主要是概念,不包含实战,所以略